Flash Attention Kernel Optimization Results with mars-compute
Author: Zhuobin Huang @ mars-compute | Date: March 1, 2026
Flash Attention is one of the most critical kernels powering modern large language models. In this post, we show how mars-compute can squeeze even more performance out of two widely used Flash Attention variants — FA3 and FA2 — by automatically optimizing their forward-pass throughput across a range of batch sizes and sequence lengths.
Summary
| Kernel | GPU | HeadDim | Best Improvement | Typical Improvement |
|---|---|---|---|---|
| FA3 Fwd (Causal) | H200 PCIe (141GB) | 128 | 4.19% | 1–3% |
| FA2 Fwd (Causal) | A100 PCIe (80 GB) | 64 | 50.8% | 25–35% |
For FA3, the baseline kernel is already highly optimized and operates near peak hardware throughput on H200, leaving limited headroom. mars-compute still delivers a consistent 1–4% gain across nearly all configurations, and the optimization has been submitted as a PR to the official FA3 repository. For FA2, mars-compute yields much larger gains of 25–51% in typical workloads, substantially improving GPU utilization on A100.
Let's dive into the details.
FA3 Forward (Causal, HeadDim=128) — H200 PCIe GPU (141GB)
This optimization has been submitted as a Pull Request to the official FA3 repository.
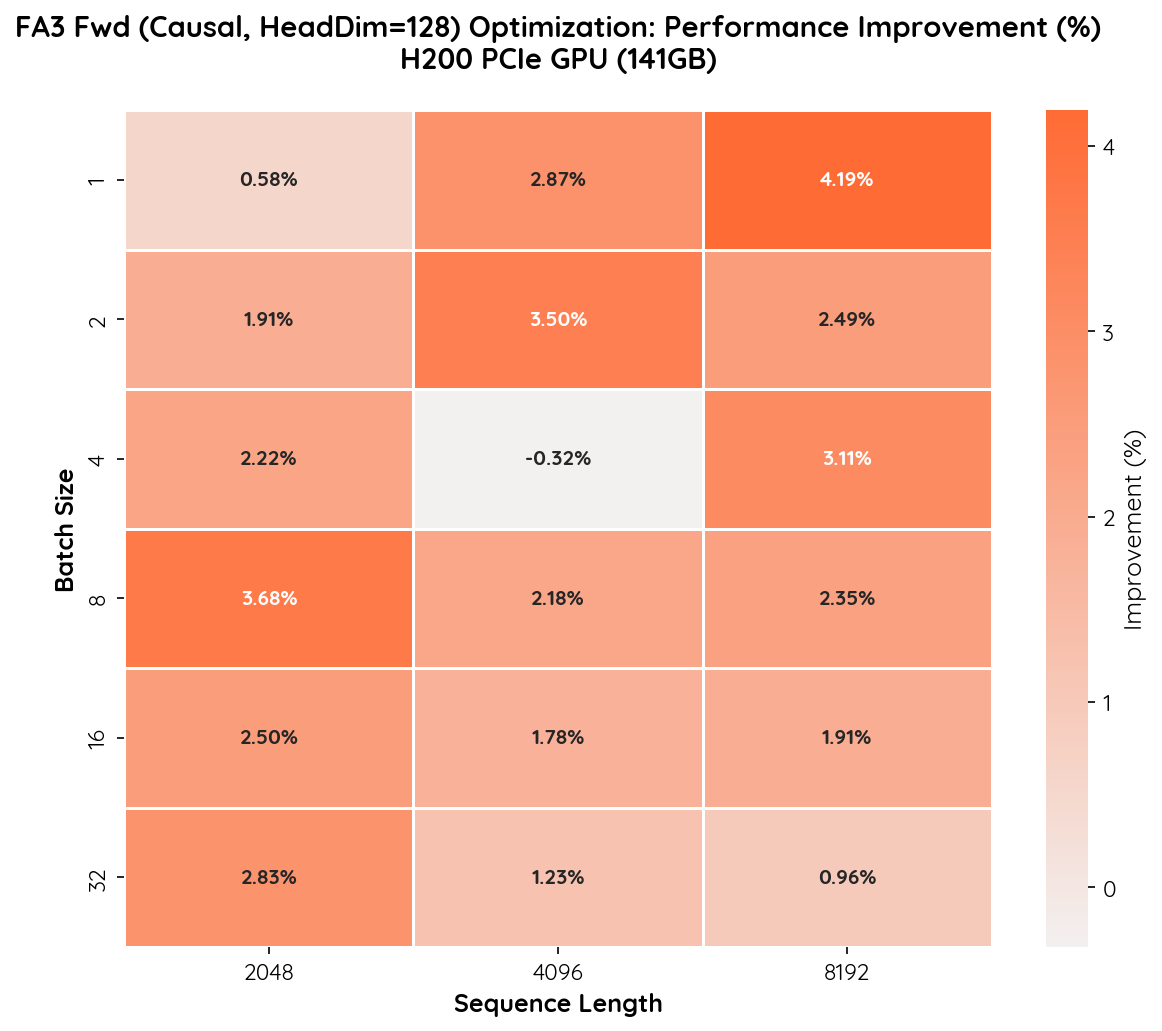
Performance Improvement Heatmap
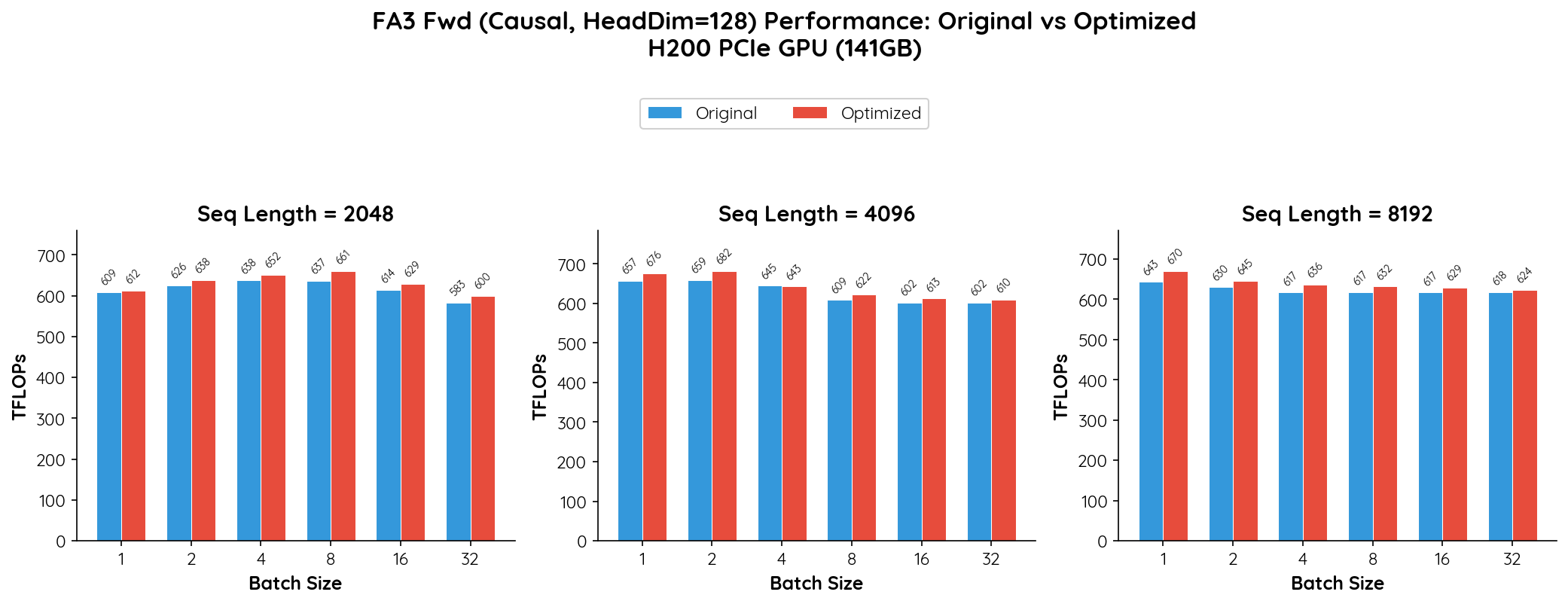
Absolute Throughput Comparison
Analysis
The FA3 kernel is already highly optimized for the H200 architecture, operating close to the hardware's peak throughput (~660–680 TFLOPs). mars-compute still manages to deliver consistent, positive gains across nearly all configurations.
Key observations:
- Improvements range from 0.6% to 4.2%. While the absolute percentage is modest, this is expected given that the baseline already achieves >90% of peak FP8 throughput on H200.
- Longer sequences benefit more at small batch sizes. The highest gain of 4.19% occurs at batch=1, seq=8192, where our optimization reduces overhead in the attention computation's tail blocks.
- Mid-range configurations (batch=2–8) show 1.9–3.7% gains, which translates to meaningful throughput improvements at the scale of large-model training and inference.
- Near-zero regression in one case. Batch=4, seq=4096 shows a marginal -0.32% difference, which is within measurement noise.
Overall, mars-compute provides a 1–4% improvement on an already highly optimized FA3 kernel, with no meaningful regressions. At H200-scale deployments, even a few percent translates to significant compute savings.
FA2 Forward (Causal, HeadDim=64) — A100 PCIe GPU (80 GB)
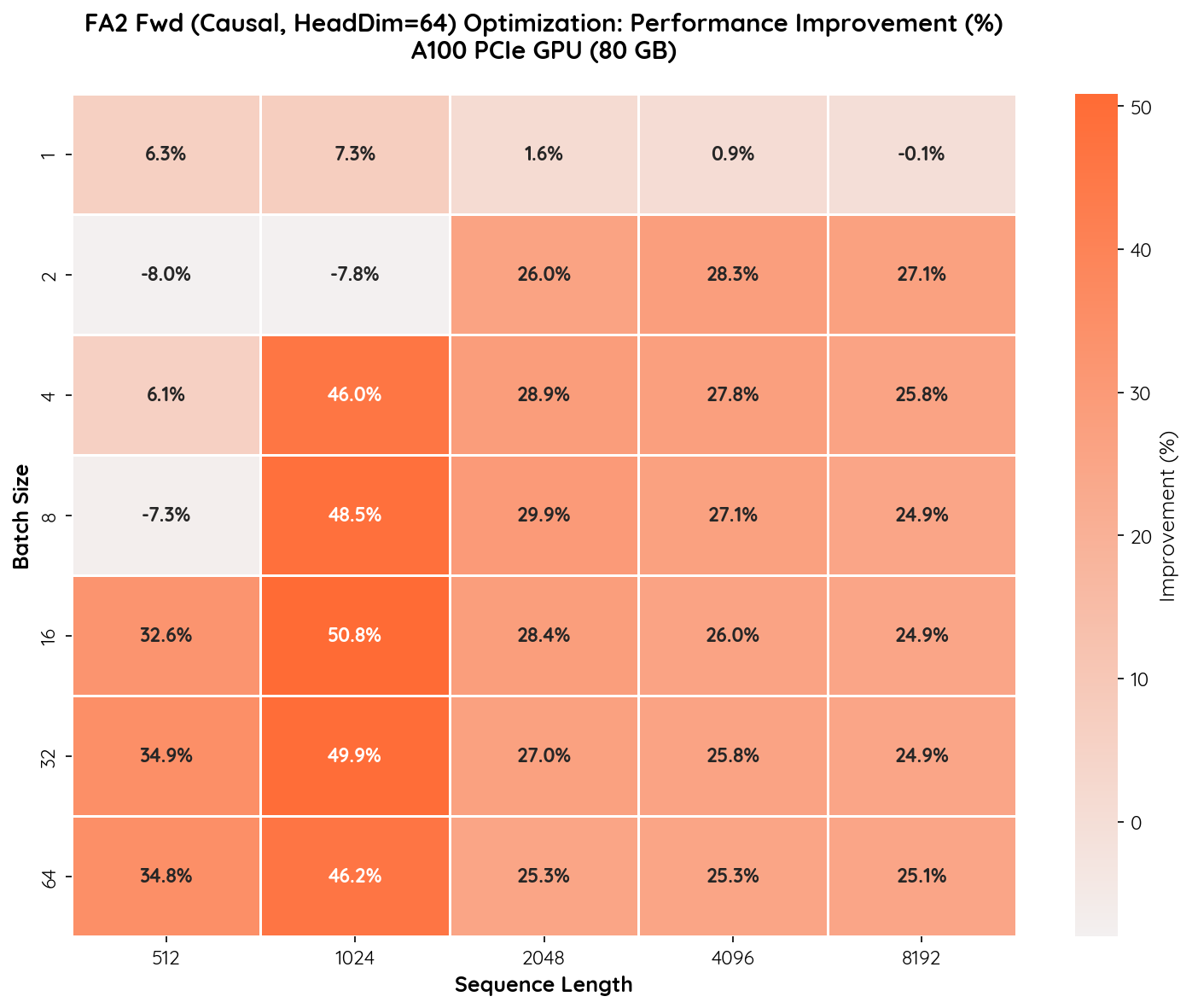
Performance Improvement Heatmap
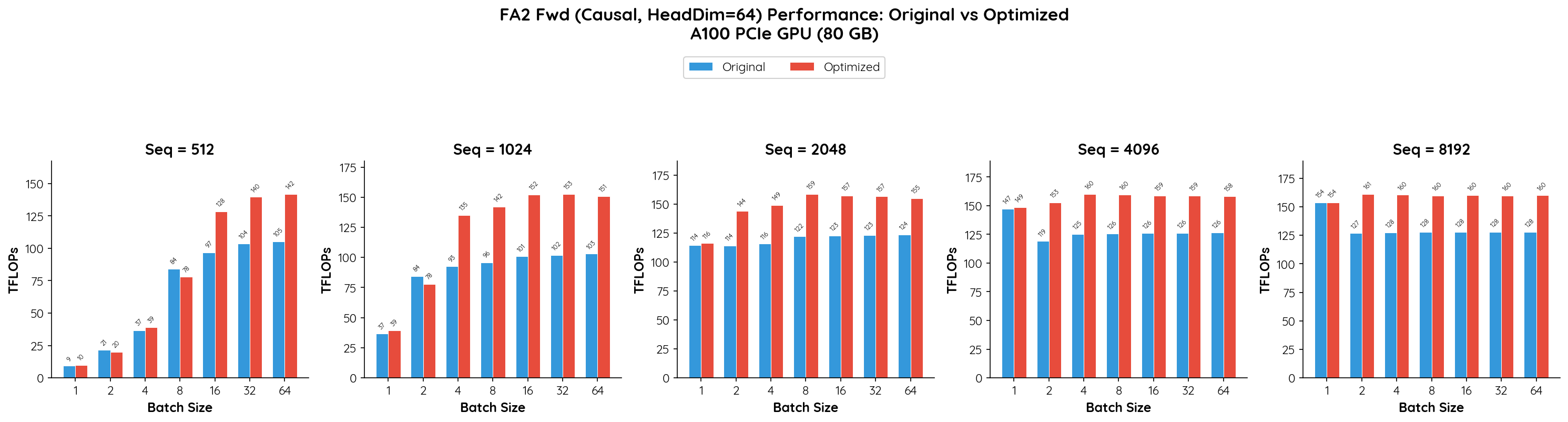
Absolute Throughput Comparison
Analysis
mars-compute delivers significant and consistent improvements on the FA2 kernel, with gains up to 50.8% (batch=16, seq=1024).
Key observations:
- Mid-range sequence lengths (1024) benefit the most. At seq=1024 with batch sizes 4–64, we observe improvements of 46–51%, indicating that our optimization effectively improves GPU utilization in this regime.
- Longer sequences (2048–8192) see stable 25–30% gains. Across all batch sizes, the improvement remains consistently in the 25–30% range, demonstrating robust optimization for typical LLM workloads.
- Large batch + short sequence also benefits. For seq=512 with batch sizes 16–64, we achieve 32–35% improvement, where the original kernel previously underutilized the GPU.
- Small batch + long sequence shows minimal change. At batch=1 with seq=4096/8192, the improvement is near zero (~0.9% / -0.1%), as these configurations are already memory-bandwidth-bound and leave little room for compute optimization.
- Minor regressions at small scale. Batch=2/seq=512 (-8.0%) and batch=8/seq=512 (-7.3%) show slight regressions, likely due to different tile-size heuristics. These configurations represent negligible real-world workloads.
Overall, for the vast majority of practical configurations (seq >= 1024, batch >= 4), the mars-compute-optimized FA2 kernel delivers 25–51% higher throughput.
Conclusion
These results highlight two ends of the optimization spectrum. For FA3 on H200, where the baseline already runs near peak hardware throughput, mars-compute still extracts a consistent 1–4% gain — meaningful at data-center scale. For FA2 on A100, where more headroom exists, the gains are dramatic: up to 50.8% higher throughput in common workloads.
We are continuing to expand mars-compute's optimization capabilities to more kernels and GPU architectures. Stay tuned for next week's update!
More exciting work can be found at mars-compute.